Response and Recovery: Handling the Global IT Outage
A detailed analysis of the response and recovery efforts following the global IT outage caused by a CrowdStrike software glitch.

A detailed analysis of the response and recovery efforts following the global IT outage caused by a CrowdStrike software glitch.

The global IT outage, precipitated by a software glitch in CrowdStrike's Falcon, posed significant challenges across various sectors. The response and recovery efforts were crucial in mitigating the impact and restoring normalcy. Here, we explore the steps taken by key stakeholders in managing this crisis.
As the scale of the outage became apparent, immediate actions were taken to contain the damage and begin the recovery process. This phase involved identifying the source of the problem and communicating with affected parties.
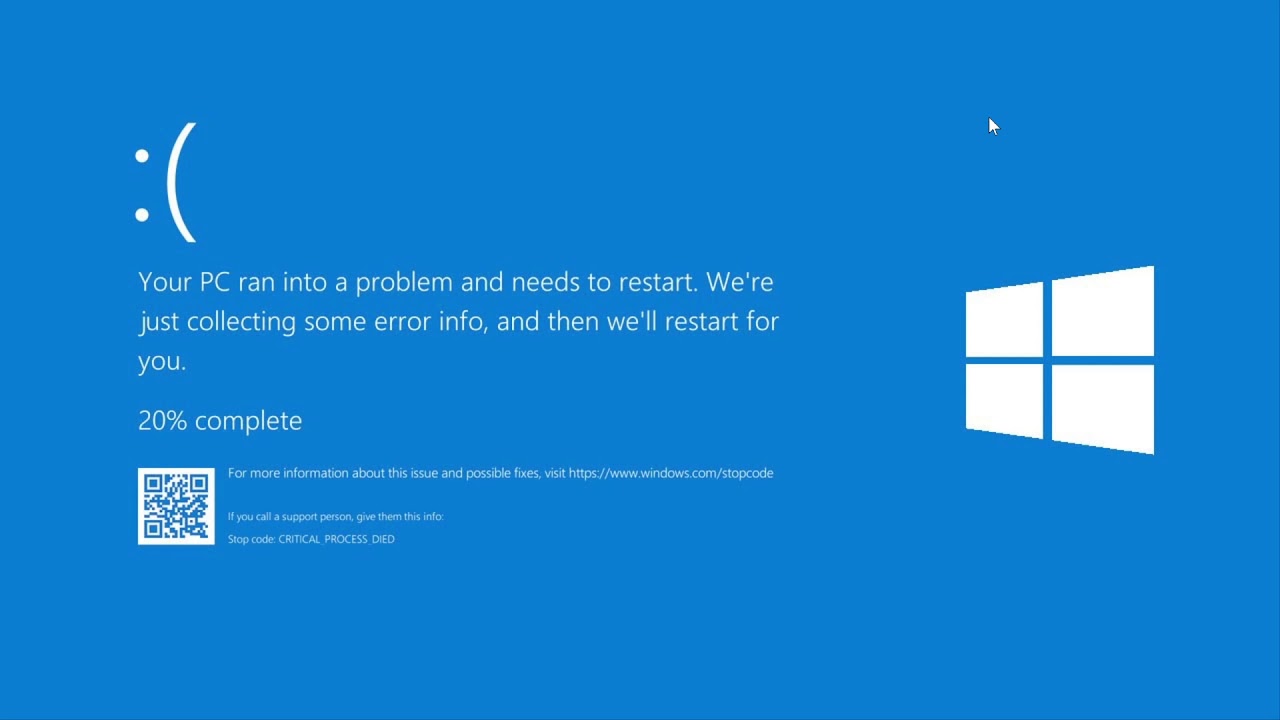
CrowdStrike quickly identified that the root cause of the outage was a defective update to its Falcon software. This update caused systems running Microsoft Windows to crash, displaying the "blue screen of death" (BSOD). Once the issue was pinpointed, CrowdStrike halted the rollout of the update and began working on a solution.
Effective communication was paramount. CrowdStrike and Microsoft both issued statements via social media and other channels to inform users about the nature of the issue and the steps being taken to resolve it. This transparency helped manage expectations and provided guidance on interim measures to mitigate the impact.
After identifying the problem, the next step was to develop and implement fixes to restore functionality to affected systems.
CrowdStrike’s engineering teams worked around the clock to develop a fix for the faulty update. This involved extensive testing to ensure that the new update would not introduce further issues.
Deploying the fix required careful coordination. Given the number of affected systems, CrowdStrike and Microsoft collaborated to roll out the update efficiently. Users were advised to reboot their systems to apply the fix, which for many involved booting into Safe Mode to rename the faulty file before rebooting normally.
During the recovery process, providing support to affected users was critical to ensure a smooth transition back to normal operations.
Both CrowdStrike and Microsoft set up dedicated support channels to assist users experiencing difficulties with the recovery process. This included providing detailed instructions and troubleshooting advice to help users apply the fix correctly.
Maintaining open lines of communication with customers helped to alleviate concerns and provide reassurance. Regular updates were issued to keep users informed of progress and expected timelines for full recovery.
The incident highlighted several important lessons for the industry:
In conclusion, the response and recovery efforts following the global IT outage were critical in restoring normalcy and highlighted key areas for improvement in incident management. The collaboration between CrowdStrike, Microsoft, and affected users demonstrated the importance of a coordinated approach in managing large-scale IT crises.


NeuralFaaruuq is dedicated to providing innovative AI and cybersecurity solutions to help businesses and individuals thrive in the digital age.